Helper functions to create new columns
Introduction
We have already covered basics of mutate operation here. There are many helper functions for creating new variables that you can use with mutate().
The key property is that the helper function must be vectorized: it must take a vector of values as input, and return a vector with the same number of values as output.
Frequently used helper functions are:
- Arithmetic operators
- Modular Arithmetic
- Logs
- Offsets
- Cumulative and rolling aggregates
- Logical comparisons
- Ranking
Procedure
We will be working with a custom dataframe.
# package for creating dataframe
library(tibble)
# tibble or dataframe with column names to rename
df <- tibble(col1 = as.integer(c(1,2,3)),
col2 = c(6.3,2.5,9.7),
col3 = c(10,100,1000),
col4 = c("string1", "string2","string3"),
col5 = as.integer(c(5, 3, 9))
)
View(df)Few rows of the dataframe are as follows:

We will be exploring the helper functions in the below section.
Arithmetic Operator Code
All arithmetic operation are vectorized, using the so-called “recycling rules.” If one parameter is shorter than the other, it will be automatically extended to be the same length.
Arithmetic Operator are +, -, *, /, ^.
# refer procedure for definition of df
library(dplyr)
arithmetic <- df %>%
# Arithmetic operators
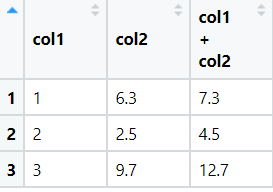
mutate(`col1 + col2` = col1 + col2) %>%
select(col1, col2, `col1 + col2`)
View(arithmetic)The output of above code is:
Modular Arithmetic Code
Modular Arithmetics include the %/% (integer division) and %% (remainder) operations. Modular arithmetic is a handy tool because it allows you to break integers into pieces.
In %/% (integer division) we get the quotient of the division. For example, 7 %/% 3 = 2.
In %% (remainder) we get the remainder of the division. For example, 7 %% 3 = 1.
# refer procedure for definition of df
library(dplyr)
modular <- df %>%
# Modular arithmetic
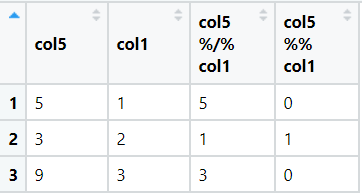
mutate(`col5 %/% col1` = col5 %/% col1,
`col5 %% col1` = col5 %% col1,) %>%
select(col5, col1, `col5 %/% col1`, `col5 %% col1`)
View(modular)The output of above code is:
Log Operation Code
Logarithms are an incredibly useful transformation for dealing with data that ranges across multiple orders of magnitude.
Log operations include log(<number>, <base>), log2(), log10().
# refer procedure for definition of df
library(dplyr)
log_result <- df %>%
# Logs
mutate(`log10 of col3` = log10(col3)) %>%
select(col3, `log10 of col3`)
View(log_result)The output of above code is:

Thus, for col3 we found its log to the base 10.
Offsets Code
lead(<vector>, <offset_by>) and lag(<vector>, <offset_by>) allow you to refer to leading or lagging values.
# refer procedure for definition of df
library(dplyr)
offsets <- df %>%
# Offsets
mutate(`lag(col3,1)` = lag(col3, 1),
`lead(col3,1)` = lead(col3, 1)) %>%
select(col3,`lag(col3,1)`,`lead(col3,1)`)
View(offsets)The output of above code is:

Cumulative and rolling aggregates Code
R provides functions for running sums, products, mins, and maxes: cumsum(), cumprod(), cummin(), cummax(); and dplyr provides cummean() for cumulative means.
# refer procedure for definition of df
library(dplyr)
cumulative <- df %>%
# cumulative and rolling aggregates
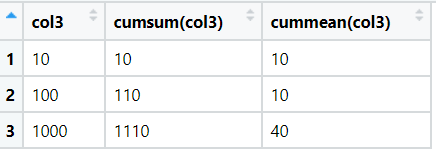
mutate(`cumsum(col3)` = cumsum(col3),
`cummean(col3)` = cummean(col3)) %>%
select(col3,`cumsum(col3)`,`cummean(col3)`)
View(cumulative)The output of above code is:
Logical comparisons Code
Logical comparisons operators include <, <=, >, >=, !=. The value returned by logical comparisons operation is boolean.
# refer procedure for definition of df
library(dplyr)
logical <- df %>%
# Logical comparisons
mutate(`col4=="string2"` = col4 == "string2") %>%
select(col4,`col4=="string2"`)
View(logical)The output of above code is:

Ranking Code
The rank operations ranks the values based on increasing or decreasing order. We use the min_rank(..) function. The default gives the smallest values the smallest ranks; use desc(x) to give the largest values the smallest ranks.
# refer procedure for definition of df
library(dplyr)
ranking <- df %>%
# Ranking
mutate(`min_rank(col2)` = min_rank(col2)) %>%
select(col2,`min_rank(col2)`)
View(ranking)The output of above code is:
![]()
If min_rank() doesn’t do what you need, look at the variants row_number(), dense_rank(), percent_rank(), cume_dist(), and ntile().
Conclusion
Thus we have successfully explored some helper functions for mutate(..).
References
- https://r4ds.had.co.nz/